
























Quotation Automation: Revolutionizing AI in Direct Procurement
AI and ML | July 13, 2022 | By
This is the first of a multi-part series on how Zumen developed a feature to extract information out of quotations and invoices. Upcoming parts will include the depth of technology used in quotation automation, the importance of this technology in the industry, and how it can solve business problems.
If you’re new to supply chain and direct material procurement, don’t worry. Our two Ultimate guides provide in-depth explanations of direct procurement.
-
-
- Direct Material Procurement Cycle Guide – Part 1: Detailed explanation of the Source-to-Contract process.
- Direct Material Procurement Cycle Guide – Part 2: Detailed explanation of the Procure-to-Pay process.
-
The Story
Before moving on with the quotation automation process, let us consider a real-time scenario. Take a Medium to Large scale product manufacturing Industry. They deal with multiple parts every day. The number of parts may range from several 10s to 1000s based on the complexity of the product.
In the New Product Development process, after finalizing the parts that will be outsourced, buyers request quotations for those parts in their Bill of Material (BOM), from different suppliers. Let us say, there are 3 suppliers for a single part. These three suppliers share their quotations via emails. Multiply this number with the number of parts outsourced. The multiplied number becomes quite staggering based on the product’s complexity. Although there are a number of procurement software’s available in the market, buyers find it difficult to manage and manually bring the data into their system. Quotations contain critical information and buyers need to analyze each one of them to make important business decisions. It is a time-consuming process where they spend most of their time transferring the information from documents into spreadsheets. Processing 100s of quotations every day is a nightmare.
This problem raises a series of questions.
Are there products or services that can reduce this manual effort?
Can we make a digital system to read and understand documents?
How do we extract information from documents seamlessly?
Do machines really understand documents with different layouts?
If we can get machines to read and understand these documents, this would bring huge operational efficiency to an organization. These documents are usually present in emails where most of the negotiations happen. We can use technology to crunch data inside the documents and give us the optimal solution but all of this data should be readily available to us.

Before analyzing these documents, it is a pre-requisite to convert them to machine-acceptable format. We need these images or paper documents translated into digital and editable formats.
This is where AI plays an important role.
How to Teach Machines to Read?
It is a fundamental challenge for machines to understand the contents of a document. Information is present in the form of characters, these characters can be the alphabet, numeric or special characters. A character does not contain any instructions for the computer. For an image document, a computer stores the ink patterns in the memory. The patterns in the image are nothing but characters. The patterns of these characters are captured as pixels which are nothing but intensity values. The technology processing these pixel data and finding the match with alphabet and numbers is called Optical Character Recognition or OCR. But it is only one piece of the puzzle, before we can get to OCR we have to understand the layout of the document.
Document understanding technology can be broken down into multiple problems:
What are the locations of different structures in the document?
How to classify these structures into tables, forms, sentences, etc.?
How do we extract the identified structures to reconstruct and arrange them into readable and editable forms for users?

In this blog we will look at different types of structures in documents and in the next blog we will look at the difficulty in reconstructing them and how ML engineers at Zumen solved the quotation automation process.
Structured Text:
Enterprise quotations and invoices can be complex documents with a lot of text and nested tables. For example, when comparing quotations to choose the best vendors or reviewing invoices to be sent for payment, a lot of data is presented in structured text. Structured data, for example, is a form with fields and values.
Industrial documents can have a lot of fields in them. Even we can find such documents, especially detailed ones, difficult to interpret. Let us rewind to the historical moment that happened at the end of WW2, after the Japanese surrender.

As the Canadian representative mistakenly signed in the wrong field, the other delegates had to sign in the next available field though it was incorrect. The Japanese delegation protested resulting in a slight tension build-up until US Chief of Staff General Richard Sutherland scratched the incorrect list and hand-wrote the correct titles under each signature adding his initials to each correction. Now if a machine is taught to understand any layout by training over it, it is less likely to make such mistakes.
Unstructured Texts
Headers, footers, numbered lists, bullet points, and paragraphs all belong to unstructured data. It can be straightforward for us to understand but machines require natural language capabilities to make sense of this type of data. Terms and conditions are a good example of unstructured text.

Understanding the context and key information from this unstructured text can be of great use for integrating them quickly with backend systems. Quotation automation can also perform tasks like Document Visual Question Answering or VQA. VQA is a machine’s ability to answer a question given an image. If this image is a document, it is Doc VQA. If we have to find the supplier contact information from the above invoice terms and conditions example, running a query directly on the document can save a lot of time. This will be particularly beneficial to quickly fetch results from unstructured text.
Tables:
A table is a compact arrangement of information in rows and columns that assists users with an easy understanding of findings and comparisons. They come in various shapes and sizes. Tables are quite literally the key structures in which companies communicate. All companies do not follow the same format for their tables. If a standard template with a properly defined grid is followed, it will be an easier problem to solve. But given the variety of shapes and border definitions it comes in, becomes an uptight problem for quotation automation. Here is an example of a complex table structure,
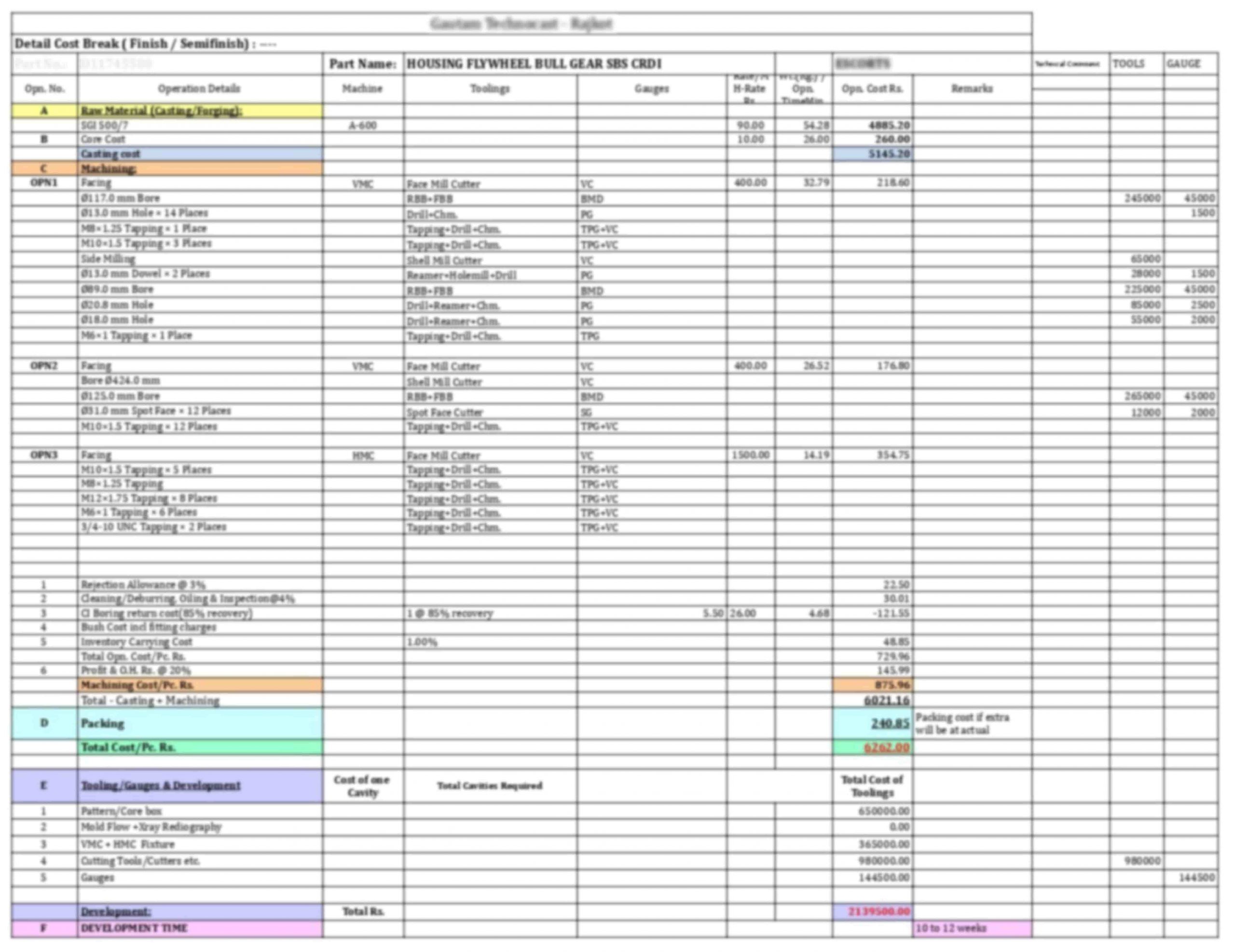
Extracting tables from documents is a multi-step problem. First, we have to find the table region and the number of rows and columns. We also need to find the words inside each cell of the table and arrange them in the right structure format. There has been significant interest in this topic in the deep learning community. Many crowd-sourced datasets are available to the public to help researchers come up with better solutions. This is the problem we set out to solve for quotation automation.
How did we solve it ?
What is the current state of accuracy and latency?
What are the pros and cons?
Stay tuned for our next part to learn more about the solution on quotation automation we designed with deep learning.