


























AI quotation: Table Extraction Deep Learning Technologies & Current Trends
AI and ML | August 04, 2022 | By
Welcome back to the second part of the Quotation Automation blog series. In the first part we looked at the need for quotation automation in organizations, the different ways data is presented in a document and the complexity involved in designing a comprehensive table extraction and document understanding solution.
If you’d like to read in detail, the full blog is here : Link
The problem we set out to solve was extracting tables from documents. Like anyone looking for a solution would, we started off by getting a lay of the land. We initially read up and later took a deep dive into the available deep learning networks, datasets and their data generation methodology, and some of the cloud solutions in the market.
*** This blog contains many Machine Learning terminologies which might need a much deeper explanation. Refer to the links provided for further reading. ***
Table Extraction Deep Learning Networks
Table Detection and Recognition is an evolving research topic with new techniques developed every year. Many conferences happen around the world to discuss the latest research ideas in document analysis. ICMLDAR , ICDAR, DAS are some of the popular ones. Some of the models we did an in-depth analysis was the following
Document Image Transformer (DiT) [Link]
One of the architectures is the DiT (Document Image Transformer) from Microsoft Research. Ever since Vision Transformers (ViT) was introduced, there has been significant interest in adapting it for computer vision tasks. DiT is an image-transformer based self-supervised model developed on large-scale unlabeled document data.
DiT uses the powerful DALL-E dVAE tokenizer by retraining it on document images for making it relevant on documents. A vanilla transformer is used as a backbone where the image is divided into patches and passed into a stack of transformers with multi headed attention. This was a better model for us to adopt as it was pre-trained on document data rather than a model that trains on general datasets. This gave us an additional performance improvement.
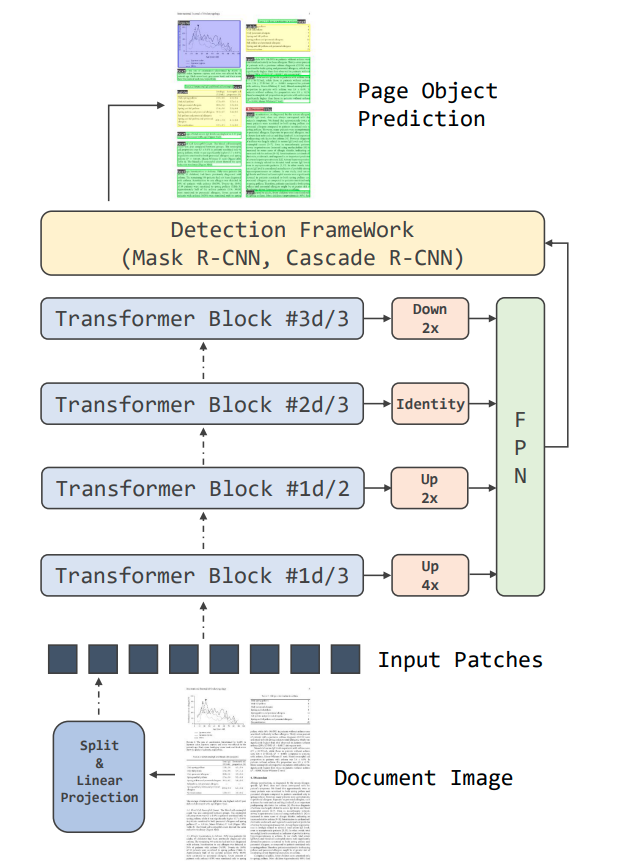
Fig 1. Source: arXiv:2203.02378 – DiT Model Architecture
During pre-training, some of the image patches are masked and encoded to learn the contextual information. The pre-training objective is to learn global patch relationships within a document. This is similar to masked language modeling (MLM) tasks in NLP. Masked Image Modeling (MIM) from BEiT is used to achieve this. The pretrained model is then used as a backbone to benchmark on different document understanding datasets like RVL-CDIP for document classification, PubLayNet for layout analysis, ICDAR 2019 for table detection, FUNSD for text detection.
To improve the performance further, the raw images are replaced with adaptive image binarization images from opencv. DiT at the time of writing this blog has the highest reported score on ICDAR with WAvg. F1 for IOU@[0.6-0.9] as 0.9655. Though this approach had better performance on table detection tasks, we had to design the structure recognition part.
TableNet [Link]
We also looked at TableNet, developed by TCS research. It is a simultaneous table detection and extraction technique that extracts the interdependence between the two tasks. The architecture consisted of a VGG-based segmentation model with an encoder branch (from conv1 to pool5) that takes image as input and trains both table and column graphs together. From this encoder branch, two decoder branches (conv7_column and conv_7_table) emerge that predict the table and column regions.
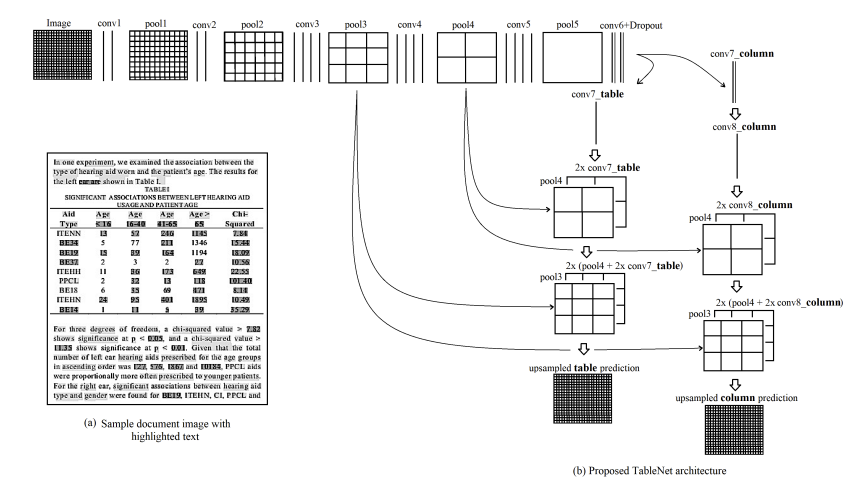
Fig. 2. Source: arXiv:2001.01469 – TableNet Architecture
For row extractions, a semantic rule-based method uses table and column predictions from the previous step. Marmot dataset is used for training and to perform column detection, columns are manually annotated. The reported metrics on the ICDAR dataset are Recall 0.628, Precision 0.9697, F1-Score 0.9547. The interesting take away for us from TableNet was the rule-based row extraction method. This gave us the idea to experiment with solving the borderless tables which we will discuss in detail in the next part.
CascadeTabNet: [Link]
Another key architecture we looked at is CascadeTabNet from PICT India. It is a complete table extraction solution. The model detects table and table cells from a document in a single inference. The model simultaneously classifies tables into bordered and borderless tables and implements different structure extraction methodology based on identified class. The below block diagram shows high level overview.
Fig. 3. Source: arXiv:2004.12629 – CascadeTabNet Block Diagram
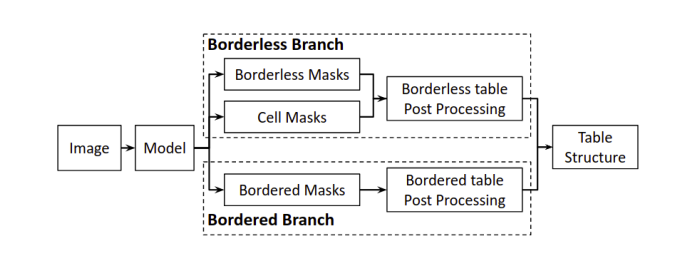
Bordered tables uses conventional text detection and line detection algorithms from opencv. For Borderless tables, structure recognition logic uses cell detections from model. In our experimentation phase, handling tables as two classes proves advantageous in getting better results when there is a clear table grid. During training, they performed a two-staged transfer learning. Transfer learning detects tables in the first iteration and cell masks for borderless tables in the second iteration. The datasets used were ICDAR 19, Marmot dataset (for training) and Tablebank dataset (for evaluation).
The reported metric on ICDAR Track A (Table Detection) is WAvg with IoU @ [0.6-0.9] and score is 0.901. For ICDAR Track B (Table Recognition), score is 0.232. We saw that CascadeTabNet has end-to-end architecture for table extraction but text recognition still missing in the solution.
Document Understanding Datasets
Deep learning models require a lot of training data for good performance. A large dataset from different domains and layouts is important to make the model generalize better. Let’s look at some of the widely used publicly available datasets that we analyzed:
TableBank [Link]
TableBank is a collection of web documents like Microsoft Word (.docx) and Latex (.tex) .These files contain table mark-up tags in their source code by nature. A special colour added in source code highlights the tables and makes them more distinguishable. Nearly 417K high quality labeled images are available in this dataset from a variety of domains like business, official filings and research papers. Two baseline models have been developed for table detection and recognition tasks. Detectron with Faster RCNN ResNeXt backbone for table detection tasks and OpenNMT-based image to text sequence model for table structure extraction.
For table detection tasks, separate models are developed for Word and Latex files. One the main observation is that Word files based models has poor performance on Latex files and vice versa showing the influence of domain on table detection. Another significant observation is that for recognition tasks the accuracy dropped dramatically for larger tables from 50% to 8.6% highlighting the importance to prevent deviations in table length distribution.
PubLayNet [Link]
This is a layout understanding dataset consisting of over 1 million PubMed Central Open Access (PMCOA) articles with layout categories like text, title, list, figure and table. The articles are XML representations and an annotation algorithm matches PDF elements with XML nodes. Multiple experiments study how different object detection models and initialization strategies influence output. A significant improvement achieved from this dataset was that pre-training on PubLayNet and fine tuning on a different domain document had better results than models pretrained on generic computer vision datasets like COCO and ImageNet.
Document Understanding Cloud Solutions
Cloud service providers like Azure, AWS and Google Cloud all have document automation services. Let’s look at the services they offer.
AWS Textract [Link]
 Textract service from AWS extracts tables, forms and text data from documents. Its OCR technology extracts handwritten text, printed texts and numbers in documents. Some of the other features include Query based extraction, Handwriting recognition, Document identification, Bounding box extractions. It also offers confidence scores and in-built human review workflow for reviewing low confidence predictions.
Textract service from AWS extracts tables, forms and text data from documents. Its OCR technology extracts handwritten text, printed texts and numbers in documents. Some of the other features include Query based extraction, Handwriting recognition, Document identification, Bounding box extractions. It also offers confidence scores and in-built human review workflow for reviewing low confidence predictions.
Azure Form Recognizer [Link]
 Azure form recognizer extracts text, key value pairs, tables and structures from documents. It provides pretrained models as well as custom development tools to finetune to any layout. Some of the prebuilt model layouts include W2 forms, invoice, receipt, ID documents, business cards.
Azure form recognizer extracts text, key value pairs, tables and structures from documents. It provides pretrained models as well as custom development tools to finetune to any layout. Some of the prebuilt model layouts include W2 forms, invoice, receipt, ID documents, business cards.
GCP Document AI [Link]
 Google cloud’s Document AI service is an automated tool to capture data from documents. The main services include form parsing, OCR, Document Splitter, Document quality assessment. There are some specialized processes like Procurement DocAI, Lending DocAI, Contract DocAI, Identity DocAI. There is a Human-in-the-Loop (HITL) feature to review outputs for critical business applications.
Google cloud’s Document AI service is an automated tool to capture data from documents. The main services include form parsing, OCR, Document Splitter, Document quality assessment. There are some specialized processes like Procurement DocAI, Lending DocAI, Contract DocAI, Identity DocAI. There is a Human-in-the-Loop (HITL) feature to review outputs for critical business applications.
Even with the availability of cloud solutions it requires a lot of machine learning expertise to deploy and maintain them. This is why we decided to create a tailor-made document processing solution to meet the needs of the procurement community.
In the next part, we will discuss in detail about how Zumen AI fixed the missing pieces of the puzzle and provided a seamless document processing AI module for quotations and invoice. Stay Tuned…..!



